
amc in Zahlen
Auf dieser Seite finden Sie eine quantitative Beschreibung der aktuellen Version. (Archivierte Informationen zu älteren Versionen finden Sie im Versionsarchiv)
Für eine Beschreibung aller hier genannten Attribute und Strukturen vgl. die Annotationsdetails
Für den Umgang mit Trefferzahlen aus Ihren Recherchen beachten Sie unbedingt die Hinweise zum Thema Normalisierung.
aktuellste Version: amc_4.24q1 (bis incl. 2024 Quartal 1 – also bis 2024-03-31)
Anzahl der Token, Words, etc.
| Counts | |
|---|---|
| Tokens | 12.487.315.613 |
| Words | 9.466.712.738 |
| Sentences | 1.038.318.869 |
| Documents | 50.491.712 |
aktuellste LTS-Version: amc_4.3 (bis incl. 2023-12)
(in der aktuellen Korpus-Nomenklatur würde man amc_4.3 als amc_4.23q4LTS benennen: die Daten reichen bis inklusive Quartal 4 2024, und es ist eine Version mit LTS — d.h. mit long term support)
Anzahl der Token, Words, etc.
| Counts | |
|---|---|
| Tokens | 12.402.137.100 |
| Words | 9.399.509.602 |
| Sentences | 1.031.383.187 |
| Documents | 50.177.372 |
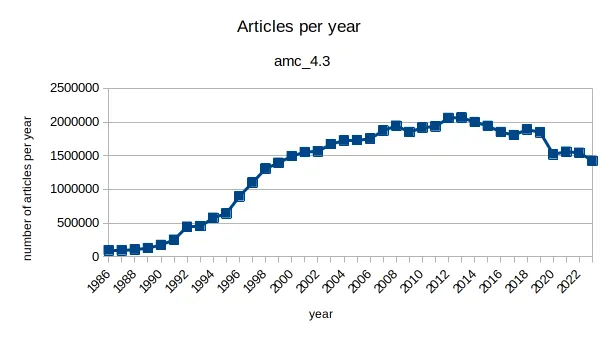
Verteilung der Artikel über die Zeit
Die Verteilung der Artikel über die Zeit ist offensichtlich unregelmäßig. Die anfangs monoton steigende Zahl der Artikel pro Jahr kann durch die „Sammlungslogik“ der APA erklärt werden: die Anzahl der in der Datenbank aufgenommenen Medien steigt im Laufe der Jahre sukzessive. In den Anfangsjahren sind nur Artikel der APA selbst vertreten, im Laufe der 1990er Jahre kommen nach und nach neue Medien hinzu.
Verteilung der Artikel auf Medientypen
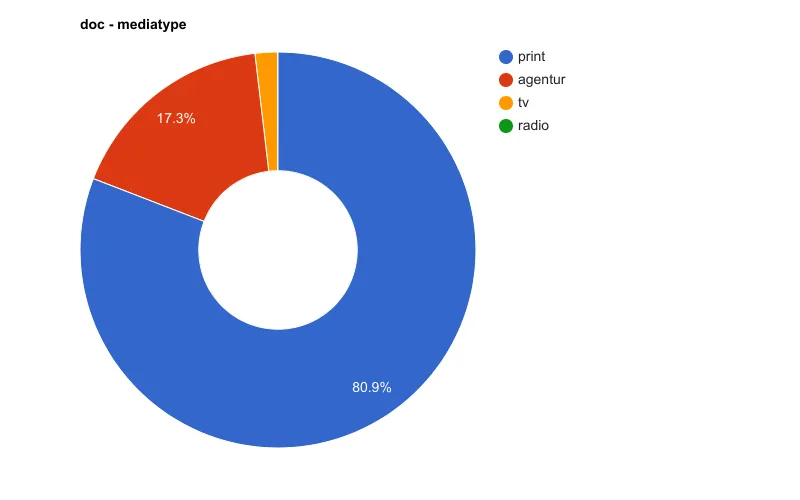
| doc.mediatype | Artikelanzahl |
|---|---|
| 40.577.867 | |
| agentur | 8.664.575 |
| tv | 914.899 |
| radio | 20.031 |
Verteilung der Artikel auf „Regionen“
Nähere Erläuterungen zur Regioneneinteilung finden sich in den Annotationsdetails
| doc.region | Artikelanzahl |
|---|---|
| agesamt | 26.612.219 |
| amitte | 3.527.856 |
| awest | 4.548.043 |
| aost | 8.823.473 |
| asuedost | 5.035.394 |
| spezifisch | 1.630.387 |